
百度SEO:百度搜索的工作原理
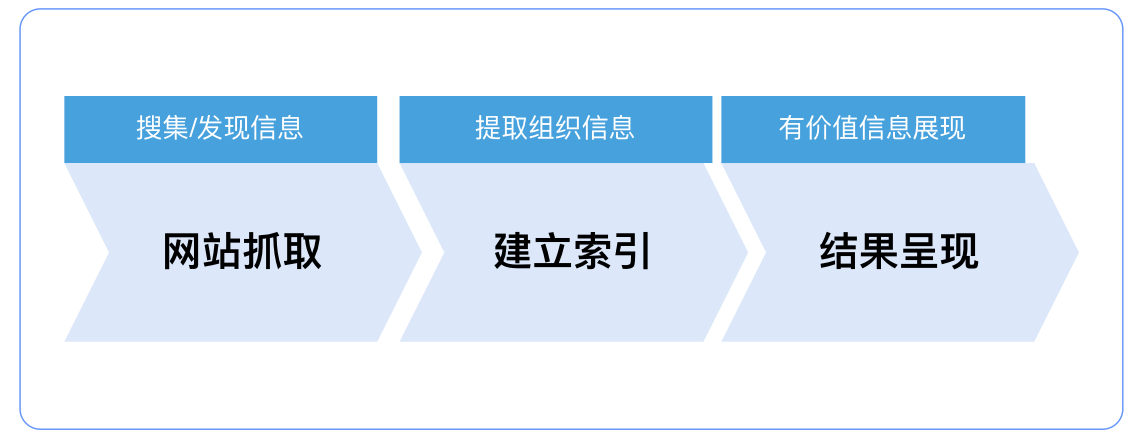
搜索引擎是根据用户需求,运用特定策略从互联网海量数据中提取对用户有价值内容的一种技术。对资源生产方而言可以简化为三步:从互联网抓取网页、建立索引数据库、将索引库中数据展现给用户。
网站抓取:在互联网中发现、搜集网页信息;
建立索引:对信息进行提取和组织建立索引库;
结果呈现:用户输入的查询关键字,在索引库中快速检出文档进行文档与查询的相关度评价,对将要输出的结果进行排序并将查询结果返回给用户。
一.网站抓取
Spider抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做Spider。例如我们常用的几家通用搜索引擎蜘蛛被叫做:Baiduspider、Googlebot、Sogou Web Spider等。
Spider抓取系统是搜索引擎数据来源的重要保证,它从一些重要的种子URL开始通过页面上的超链接关系不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型Spider系统,因为每时每刻都存在网页被修改、删除或出现新的超链接的可能,因此还要对Spider过去抓取过的页面保持更新。
当Baiduspider无法正常抓取时,会出现抓取异常。对于大量内容无法正常抓取的网站,搜索引擎会认为网站存在用户体验上的缺陷并降低对网站的评价,抓取、索引、权重上都会受到一定程度的负面影响,最终影响到网站从百度获取的流量;
抓取过程中Baiduspider会根据网站内容更新频率和服务器压力等因素自动调整抓取频次。如果搜索引擎对站点抓取超过服务压力,网站可以通过抓取频次工具进行调节。如果有不想被搜索引擎抓取的部分或者指定搜索引擎只抓取特定的部分,可以进行Robots设置;同时为了提升百度蜘蛛抓取数据的效率,我们可以通过收录工具将资源主动提交给百度;
二.建库索引
前面Spider进行了一轮筛选之后,数据量依然巨大。这时候由索引系统对收集回来的网页进行分析,提取相关网页信息,根据一定的相关度算法进行大量复杂计算得到页面内容中及超链中每一个关键词的相关度或重要性信息,然后利用这些相关信息建立网页索引数据库,将有价值的资源保存下来。
2.1新站的站长常常会遇到整站未被索引的情况,这种怎么解决?
站点内容页面需要经过搜索引擎的抓取和层层筛选后方可在搜索结果中展现给用户。Baiduspider抓了多少页面并不是最重要的,重要的是有多少页面被建索引库即我们常说的“建库”。众所周知搜索引擎的索引库是分层级的,优质的网页会被分配到重要索引库,普通网页会待在普通库,再差一些的网页会被分配到低级库,低级库展现的机会较小。
2.2那么哪些网页可以进入优质索引库呢?
其实总的原则就是一个:对用户的价值。包括不限于:
1、领域垂直聚焦:当内容生产者在输出内容时,涉及的领域不应该过杂,不应该浪费精力去生产堆砌不熟悉的内容。应在专业领域内生产专业的内容,聚焦并把最擅长的内容做好,有利于持续满足用户的同类型需求。
2、内容质量高:表述清晰阅读顺畅 ,文笔用词用句舒适,行文严谨考究,能体现这个行业的专业性,实操性强。
3、高价值原创:百度把原创定义为需花费一定成本、大量经验积累提取后形成的文章。
4、体验舒适使用流畅:排版布局合理,考虑用户体验,不能阻塞用户的顺畅浏览,减少不必要的阅读权限设置等。
具体更多的内容可以参照优质内容规范以及百度APP移动搜索落地页体验白皮书5.0
同时互联网上有一部分网站根本没有被百度索引,可能存在以下原因:
1、重复内容的网页:互联网上已有的内容,百度没有必要再索引
2、主体内容空短的网页
3、违规作弊站点等
最后我们可以通过索引量工具查看站点中有多少页面可以作为搜索候选结果,就是一个网站的索引量数据。
三、结果呈现
用户输入关键词进行检索,百度搜索引擎在排序环节需要做两方面的事情,第一是把相关的网页从索引库中提取出来,第二是把提取出来的网页按照不同维度的得分进行综合排序。“不同维度”包括不限于以下几个维度,具体可以通过优质内容规范了解;
1、相关性:网页内容与用户检索需求的匹配程度
2、权威性:用户喜欢有一定权威性网站提供的内容,相应的百度搜索引擎也更相信优质权威站点提供的内容
3、时效性:时效性结果指的是新出现的网页且网页内承载了新鲜的内容。目前时效性结果在搜索引擎中日趋重要
4、内容质量高:表述清晰阅读顺畅 ,文笔用词用句舒适,行文严谨考究,能体现这个行业的专业性,实操性强
以上便是百度搜索引擎决定搜索结果排序时考虑的一些原则,同时我们可以通过资源平台-【搜索服务】下工具,如站点子链,站点属性,及网站改版等工具提升网站的展示效果。
想了解更多SEO技术的内容,请访问:SEO技术




")






")

